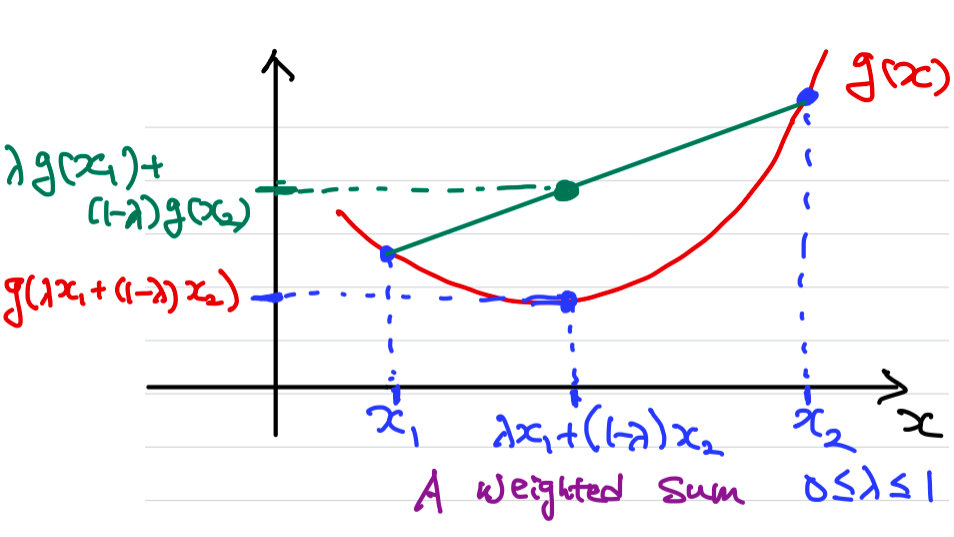
A function is convex if and . is called strictly convex if the equality holds only for , or . I.e., the graph of over contains no straight lines.
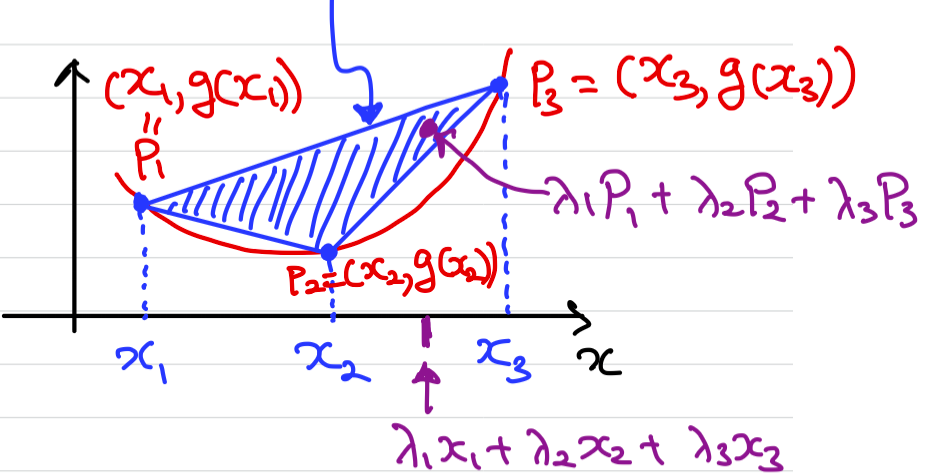
Now consider three points . The convex hull of is
This is a triangular area of the three points. If is convex, by the figure
We can conclude for multiple points:
2 Jensen's Inequality
Theorem (Jensen's Inequality)
A convex function satisfies for all satisfying .
Proof
We perform induction on .
, obvious by definiton.
Assume true for . Then for ,
((*): definition of convexity; (**): induction assumption.)
Corollary
Let be a valued discrete RV and a convex function. Then if is strictly convex and is not constant, then
Proof
Let in Jensen's inequality.
3 Entropy
Suppose are two probability measures on , and a discrete RV, s.t.
Shannon Entropy
Cross Entropy
The cross entropy of relative to is
KL Divergence
The KL divergence (Kullback-Leibler divergence) of from is
For continuous RV, replace with p.d.f and with . I.e.
In general, .
We can use Jensen's inequality to prove KL divergence is non-negative. See below.
To solve the problem of asymmetry, we define JS divergence: